The problem with near-realtime search and update-by-query.
In the startup I work for we’re evaluating the usage of elasticsearch to search for file metadata. Recently, when writing an integration test I’ve found an interesting bug, which I missed when designing the solution. We use the update-by-query plugin to bulk update docs. In test I wrote I added a document and immediately updated it. The thing is that the document was not being update. What happened? Read on…
Elasticsearch is backed up by lucene and each field is a lucene index. Lucene doesn’t offer real-time search. Instead they have something they call near real-time search (short: NRT). The reason for this is that a lucene commit to disk is an expensive operation, so in order to have decent performance this can’t happen too often. They work around it by using a memory buffer which keeps incoming documents until they are committed.
Unfortunately, this also doesn’t meet the NRT requirements as the cost
is too high to commit often. The solution is the refresh operation,
which doesn’t commit the incoming documents to disk, but closes and
reopens the index reader making the documents available for
search. This is a much cheaper operation. Elasticsearch adds an
additional transaction log to make sure that all the incoming
documents are not lost between the commits.
You can control how often the refresh happens at the index level or
issue the refresh operation manually.
Incoming documents:
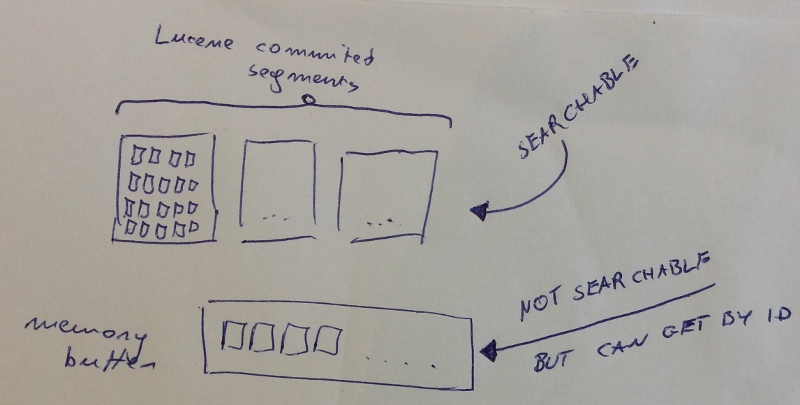
After the refresh operation:
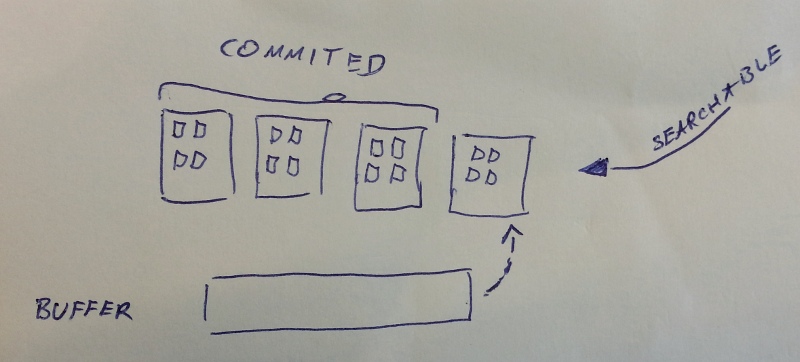
Back to our original problem. The way _update_by_query works is that
it first search for documents and then applies an updating script to
each one of them. Probably you can see the issue already :-).
The problem was that we did the query before refreshing the index. In real world this won’t happen then often, as update-by-query is a pretty rare operation and also doesn’t happen right after adding new documents. Nevertheless, we have to solve it.
Right now I see two solutions. (1) Change the update by query to update by id where possible. This works because documents in the memory buffer are accessible by id. (2) For all the cases where update by query is really required prepend it with the refresh operation.
For the latter solution we need to check the performance impact of adding the additional refreshes.
Sources and related material:
>> Home