ECONNREFUSED on every deploy: draining gRPC connections
We’ve received customer reports of workers producing bursts of UNAVAILABLE: No connection established. Last error: connect ECONNREFUSED x.x.x.x:xxxx in the logs. UNAVAILABLE is the canonical gRPC transient failure code and ECONNREFUSED is a lower-level TCP error meaning the SYN went out and an RST came back: the destination was reachable, but nothing was listening on the port.
This article is a fast-track guide/checklist for debugging deployment-adjacent availability with gRPC servers on Kubernetes. There are a lot of good articles on the graceful shutdown of HTTP servers (I can recommend EKS Best Practices Guide: Load Balancing), but gRPC is a road less traveled. If you’re debugging this right now, jump to the self-diagnosis table at the end.
The symptom #
The workers connect with the Hatchet engine (the task-queue server we run) over gRPC. For the setup I’m describing, the engine runs as pods on Kubernetes, and there’s an AWS Network Load Balancer in front.
We were able to correlate these UNAVAILABLE bursts to Hatchet Engine deploys. We checked the basics: there was a SIGTERM handler with reasonable cleanup order and grace period, the NLB had a health check endpoint; it looked OK on the surface. However, we needed a mix of both in-process and out-of-process fixes to solve this.
The fan-out #
So what happens when we run kubectl rollout restart deployment/xyz? kubectl patches the Deployment’s pod template with an annotation kubectl.kubernetes.io/restartedAt: ... The Deployment controller sees the pod template hash change and initiates a rolling update: scale up the new pods and scale down the old. Here we will focus on the scale-down aspect. It’s identical to kubectl delete pod — the API server sets deletionTimestamp and metadata.deletionGracePeriodSeconds in the Pod object.
The key thing about Kubernetes is that it’s eventually consistent. There are multiple watches which act on that deletionTimestamp: .. and nothing sequences them.
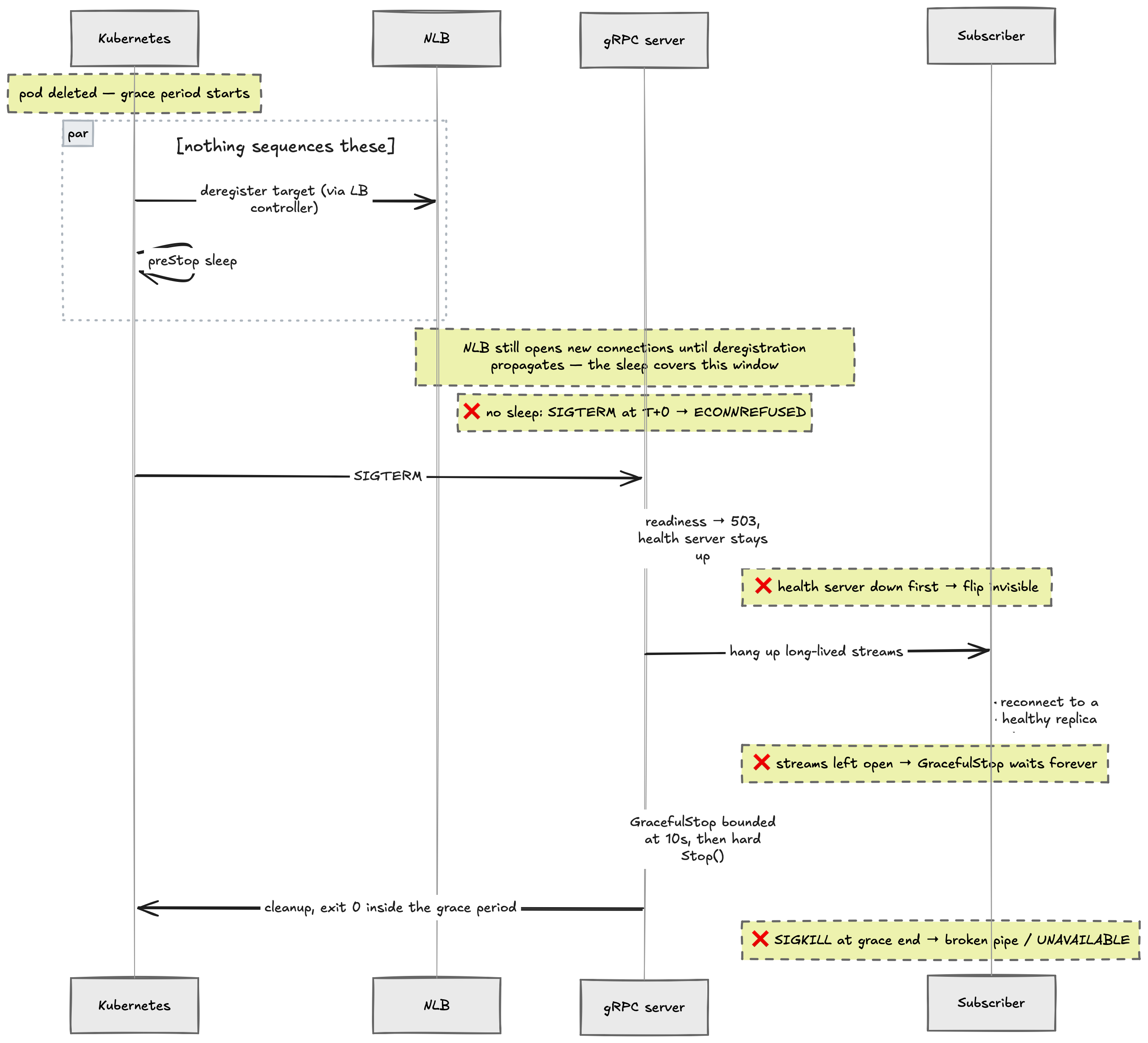
Three watchers act on the deletion — the kubelet, kube-proxy, and the load balancer controller:
Branch 1: kubelet. The kubelet on the node sees the update and runs the
preStophook if it exists. After the hook completes, it sends SIGTERM to PID 1 of each container in the pod. Aftermetadata.deletionGracePeriodSecondsthe kubelet sends SIGKILL. ThepreStopis the only place to “hook” custom code before the SIGTERM and SIGKILL countdown.Branch 2: EndpointSlice controller. It sees the same event, and marks the pod’s endpoint as
Terminating: TrueandReady: False.Branch 2a: kube-proxy. (Or your alternative for in-cluster traffic). The kube-proxy on every node watches the changes on the EndpointSlice, and drops it from the iptables rules to stop sending traffic to the pod backing it.
Branch 2b: AWS Load Balancer Controller is even more complex. If you are on a different provider, it will have a similar shape:
- The LB controller watches Endpoints/EndpointSlices, and maintains a mapping of pod IPs to target groups. (This applies to
target-type: ip;target-type: instanceis slightly different and skipped here). - The event of the EndpointSlice
Terminatingflipping toTruelands in the controller queue. - The controller calls the
DeregisterTargetsAPI, over the network to the AWS control plane, which triggers a state change of that target todraining. - After a configuration propagation delay all the NLB’s nodes in the fleet stop routing new connections to that backend.
- Independently, the
deregistration_delaytimer starts (defaults to 300s); after it finishes the NLB sets the target status fromdrainingtounused, but by default it doesn’t kill the existing connections at all (!).
- The LB controller watches Endpoints/EndpointSlices, and maintains a mapping of pod IPs to target groups. (This applies to
It’s quite a few steps to stop new connections from reaching the pod being terminated, and this branch races with the kubelet branch, which is about to send a SIGTERM. The pod can receive SIGTERM, run a textbook shutdown, close its listeners and exit, all well before the AWS Load Balancer Controller branch finishes.
The fix outside the process #
The pod cannot observe branch 2b. There is no signal for “every NLB node has stopped routing new connections here”, so the only available move is to delay the SIGTERM long enough for deregistration to propagate.
We can do that with a sleep in the preStop hook. The kubelet runs the hook to completion before sending SIGTERM, and the process keeps serving normally through the whole sleep while the LB controller and the NLB fleet catch up. This used to require a shell in the image for exec sleep 20; KEP-3960 (stable in k8s 1.34) made sleep a native field, which tells you how widespread this hack pattern was.
spec:
terminationGracePeriodSeconds: 75 # covers preStop + drain + cleanup
containers:
- name: engine
lifecycle:
preStop:
sleep:
seconds: 20 # covers deregistration propagation
The sleep is open-loop (a guess on propagation time, with no feedback). The closed-loop backup is the NLB health check (the NLB observes the health check endpoint). The pattern is to point it at the readiness endpoint. When the process flips readiness to 503 on SIGTERM, any NLB node that has yet to process the deregistration marks the target unhealthy within ~10 seconds (depending on the configuration) and stops routing new connections on its own.
We had ours pointed at the liveness endpoint, which stays green for the entire teardown; a health check on liveness verifies the pod is running, and a terminating pod is running even when it can’t accept new connections.
One caveat: keep the health server up until the end of teardown. If the shutdown sequence tears down the HTTP server early, the LB never observes the 503 and the readiness flip is invisible.
# Service annotations (AWS Load Balancer Controller)
service.beta.kubernetes.io/aws-load-balancer-healthcheck-protocol: http
service.beta.kubernetes.io/aws-load-balancer-healthcheck-path: /ready # not /live
service.beta.kubernetes.io/aws-load-balancer-healthcheck-interval: "5"
service.beta.kubernetes.io/aws-load-balancer-healthcheck-healthy-threshold: "2"
service.beta.kubernetes.io/aws-load-balancer-healthcheck-unhealthy-threshold: "2"
service.beta.kubernetes.io/aws-load-balancer-target-group-attributes: deregistration_delay.timeout_seconds=60,deregistration_delay.connection_termination.enabled=true
Things to note:
- The grace period countdown includes the
preStopsleep, soterminationGracePeriodSecondsmust cover sleep + drain + cleanup with a headroom. E.g. a 20s sleep inside the default 30s grace leaves 10s for everything else — so even a textbook shutdown gets SIGKILLed if draining takes longer than that. - Set the target-group attributes: the default
deregistration_delayis 300s and the NLB never terminates the draining connections, so tweak it and enableconnection_terminationto get an upper bound on how long old connections linger.
The fix inside the process #
The process itself has to exit inside the grace period. Our SIGTERM handler looked fine: flip readiness, stop the gRPC server with GracefulStop, and run the rest of the cleanup.
It failed to terminate before the SIGKILL on every rollout anyway. The reason is in the GracefulStop contract: it sends GOAWAY, refuses new RPC connections/streams, and then waits for all in-flight RPCs and streams to finish. This is fine for unary RPCs (they are a bit like HTTP requests). Long-lived subscriber streams finish when the client hangs up; in this case that means never (the client has no idea the server wants to leave).
The fix has two parts. First, hang up the long-lived streams server-side before calling GracefulStop: each streaming handler registers its context cancel function on the way in, and the gRPC teardown needs to cancel all of them. With that change, the clients see their streams end, reconnect, and land on a healthy replica (because of the readiness work from the previous section).
Second, bound GracefulStop:
cleanup := func() error {
stopped := make(chan struct{})
go func() {
defer close(stopped)
grpcServer.GracefulStop()
}()
select {
case <-stopped:
l.Debug().Msg("grpc server stopped gracefully")
case <-time.After(shutdownTimeout): // 10s default
l.Error().Msgf("grpc did not drain within %s, forcing a hard stop", shutdownTimeout)
grpcServer.Stop()
<-stopped
}
return nil
}
The error log will catch any stream we’ve missed during the cancellation, so we can fix that.
Self-diagnosis table #
| Symptom | Cause | Fix |
|---|---|---|
UNAVAILABLE / ECONNREFUSED bursts on every deploy | The LB keeps routing new connections to the terminating pod; deregistration hasn’t propagated when SIGTERM lands | Fix outside: preStop sleep sized to propagation, readiness-based health check as backup |
| Pod always survives till SIGKILL despite a “graceful” handler | GracefulStop waits on long-lived streams that only the client can end | Fix inside: hang up streams server-side, bound GracefulStop with a hard Stop() fallback |
| Readiness flips to 503 but the LB never reacts | Health check points at liveness (a terminating pod is alive), or the health server is torn down early so the flip is invisible | Point the LB health check at readiness; keep the health server up until the end of teardown |
| Errors persist even with a huge grace period | The grace period starts at pod deletion and only governs the SIGKILL; the LB doesn’t observe it at all | Fix outside: the preStop sleep is what buys deregistration time, not the grace period |
| Old connections linger minutes after the pod is gone | NLB deregistration_delay defaults to 300s and never terminates draining connections | Set deregistration_delay.timeout_seconds and enable connection_termination |
The in-process changes described here shipped in hatchet-dev/hatchet#4139.
References #
- KEP-3960: Sleep Action for PreStop Hook
- Learnk8s: Graceful shutdown and zero-downtime deployments
- hatchet-dev/hatchet#4139 — drain grpc streams and bound graceful shutdown