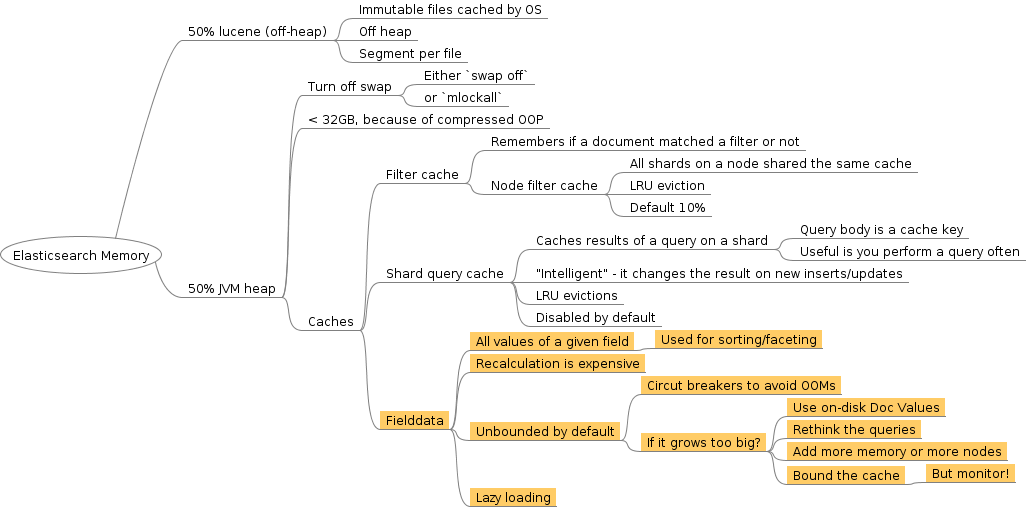
Elasticsearch Caches - Fielddata
Exploring elasticsearch caches and memory usage - fielddata.
UPDATE this blogpost was written for elasticsearch 1.6 and it is no longer up-to-date.
One of my production clusters got recently hit by the
CircuitBreakerException Data too large exception. In this post we’ll
explore the Fielddata cache, Circuit Breakers and what we can do
to avoid Fielddata eating all of our precious heap space. This a
first article in a short series on
elasticsearch memory usage.
We saw this exception
CircuitBreakingException[Data too large, data for field [canonicalFolderPath] would be larger than limit of [19285514649/17.9gb]
Let us tackle this step by step.
Parts of the puzzle
Fielddata #
Elasticsearch has a concept of Fielddata. It is a set of all
possible values/tokens of a field. Since it is expensive to compute,
especially for larger fields, it is cached in-memory. In case of our
exception, Elasticsearch tried to load Fielddata for
canonicalFolderPath field.
Fielddata are used for sorting and aggregations. Indeed, the query
which triggered our exception facilitated aggregations to count number
of documents with the same canonicalFolderPaths.
Elasticsearch uses Guava Cache internally and two settings can be configured:
- size: defaults to unbounded; this is the upper limit on cache
size either absolute, e.g.
1GBor relative to the heap size, e.g.30% - expire: defaults to
-1, so never expire; can be set to expire after some inactivity time, e.g.3h
Please note that there used to be a bit different settings for this
cache in older Elasticsearch versions. Some good on-line material on
tuning the Fieldcache is no longer accurate (for example
this post from sematext blog,
it is a very good reading, but you do not set resident versus soft
or the number of entries anymore; just set the size and you’re done).
You can read more in the
Fielddata documentation
or, if you are curious how exactly the Guava cache is used
consult the source.
Circuit Breakers #
Leaving a cache unbounded eventually leads to OutOfMemory
exceptions. To avoid them Elasticsearch implemented
Circuit Breakers. The
idea is to throw an exception before an operation will lead to OOM
condition.
There are couple of levels of circuit breakers, but in the context of
our exception the import one is Field data circuit breaker. It kicks
in when loading a field into Fieldcache would result in over 60% of
heap memory usage for Fieldcache and it prevents such operations
from completing by throwing the exception we saw above. Of course,
this 60% is configurable.
Solutions
Now we now the landscape, so let us think what are the possible solutions.
Add more memory or more nodes #
The larger the heap, the more space for field data cache. More nodes
have similar effect as the shards are spread into more machines thus
also the cache is spread into more nodes. If you don’t expect your
indexes size to grow much more this is probably the best option
— Fielddata will remain cached in memory and your queries
will be blazing fast.
Bound the cache #
By setting an upper limit on the cache size, Elasticsearch evicts the
least recently used entries if the cache is close to its limit, thus
preventing the circuit breaker to kick in. It comes at a price
though. In case of frequent evictions and Fielddata recalculations
the query performance may be really poor (for sorting or aggregating
queries).
Data too large exception is a clear sign that something is wrong
— you need more memory or you need to redesign your
queries. With a cache upper bound you’ll get away with your current
queries and memory, but some of the queries will take a long time (few
minutes compared to few seconds).
Luckily, not all is lost. You may bound the cache and monitor
evictions. In case you see a lot of them this means you need to do
something to save the performance. Try the other options presented
here. You can monitor the Fielddata size and evictions using the
nodes stats api
or in the node diagnostics screen of
HQ plugin
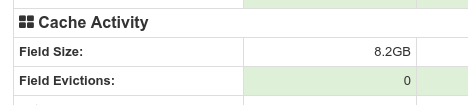
What is the perfect limit? There is no good answer. Various on-line article suggests something between 50–70%. You need to consider your needs, pick a setting and monitor it.
Redesign your queries #
This solution really depends on your use case, but maybe you do not need to use aggregations on all the fields or maybe you can simply eliminate some of the queries?
Use Doc Values instead of Fielddata #
Since version 1.0, Elasticsearch lets you can use an on-disk
Fieldata equivalent —
Doc Values. In
the 1.4+ version they are quite fast — only 10-25% penalty
compared to Fieldata — and are recommended over them. What
are the drawbacks? First of all, you need to set this up in the index
mapping before you start indexing your data. Secondly, this will not
work for full-text search fields, only for not_analyzed.
The rule of thumb should be to use Doc Values wherever possible for new deployments. Consult the documentation on how to set up your mapping.
Conclusions
To sum up, we’ve learned what are the Fieldata and how Circuit
Breakers save Elasticsearch from running into OOM conditions. We
discussed couple of options on what to do when your Fieldata eats
too much of your heap. Sometimes, the only
winning move is not to play
at all. This is true for =Fielddata=, it’s best to use =Doc Values=
instead. Unfortunately, this is not always possible. If you can’t
redesign your queries or spare some more memory then you have no other
options than to bound the cache size and monitor what happens.