Make Go application container resource limits aware
Go binaries are not inherently container-aware, specifically in that they do not account for memory and CPU limits.
TL;DR
When running a Go application in a container with set CPU or memory limits, you should inform the Go runtime of these limits using the GOMAXPROCS and GOMEMLIMIT environment variables.
For example, if you run your application as follows:
docker run --cpus="4.0" --memory="2000m" my-go-app
Inform the Go runtime as follows:
docker run --cpus="4.0" --memory="2000m" -e GOMAXPROCS=4 -e GOMEMLIMIT=1800m my-go-app
Memory
Docker and Kubernetes use cgroups to enforce memory limits, which means that if a process requests more memory from the OS than its assigned limit, it may be terminated by the oom-killer (which is the out-of-memory subsystem of the Linux kernel):
The memory limit defines a memory limit for that cgroup. If the container tries to allocate more memory than this limit, the Linux kernel out-of-memory subsystem activates and, typically, intervenes by stopping one of the processes in the container that tried to allocate memory. If that process is the container’s PID 1, and the container is marked as restartable, Kubernetes restarts the container.
Go runtime allocates objects on the heap until the heap runs out of memory, at this point it asks the OS for twice the size of memory. If your current heap is 100M, when your application fills it up, the Go runtime will resize it to 200M, then to 400M, 800M, etc.
At this point, Go also triggers the garbage collection, but the extra heap is already requested from the OS, which may trigger an oom-killer. This may happen even if the live heap stays below the cgroups memory limit.
GOMEMLIMIT gives the Go runtime a target to hit. The new heap won’t exceed GOMEMLIMIT as long as the live heap fits in. Of course, it’s not a miracle; if there’s only a little room left above the live heap, the garbage collector will need to run more often, potentially introducing a lot of latency. It’s also a “soft” target; if the live heap needs more memory than GOMEMLIMIT it will still ask the OS for it (which will trigger the oom-killer).
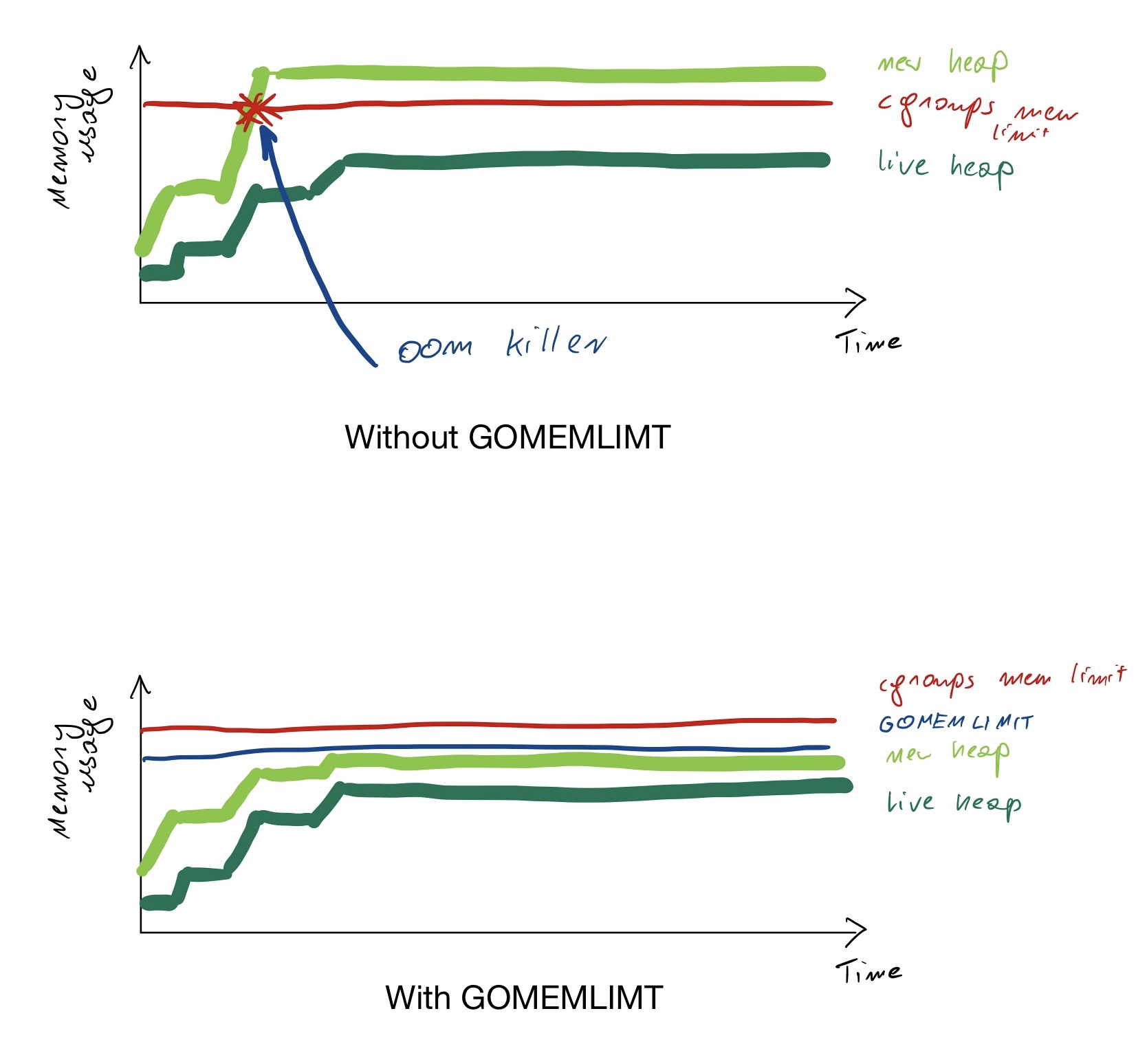
Do take advantage of the memory limit when the execution environment of your Go program is entirely within your control, and the Go program is the only program with access to some set of resources (i.e. some kind of memory reservation, like a container memory limit).A good example is the deployment of a web service into containers with a fixed amount of available memory.In this case, a good rule of thumb is to leave an additional 5-10% of headroom to account for memory sources the Go runtime is unaware of.
As an alternative, you can configure the memory target within the code at runtime. The KimMachineGun/automemlimit library can automatically tie the memory target to the cgroups memory limit.
CPU
The impact of setting CPU shares and quotas (requests and limits in Kubernetes terminology) is fascinating. I recommend the following articles on the subject: (1) “The container throttling problem” by Dan Luu discusses the impact of CPU limits on tail latency of servers within Twitter, (2) “For the Love of God, Stop Using CPU Limits on Kubernetes” by robusta discusses that it may be better to set only requests, but not limits. Specifically for Go, check (3) “Go, Containers, and the Linux Scheduler” by River Phillips.
Go runtime will create a thread for each CPU core your machine has; it won’t scale it down to your CPU requests/limits. These threads run garbage collection and execute goroutines.
CFS (the Linux scheduler) works in periods (typically of 100 ms). The total CPU time available during the period is 100ms * number of cores (say 400ms on a 4 vCPU machine). If you configure CPU quotas (e.g. with the docker --cpus=2 flag, or with Kubernetes limits), your process will get a fraction of the total time (200ms in our example).
If four threads run simultaneously (e.g., performing garbage collection), they will consume the allotted 200ms in the first 50ms of the period. This means that the application will be waiting and doing nothing for the next 50ms until the next period starts. This is illustrated below:
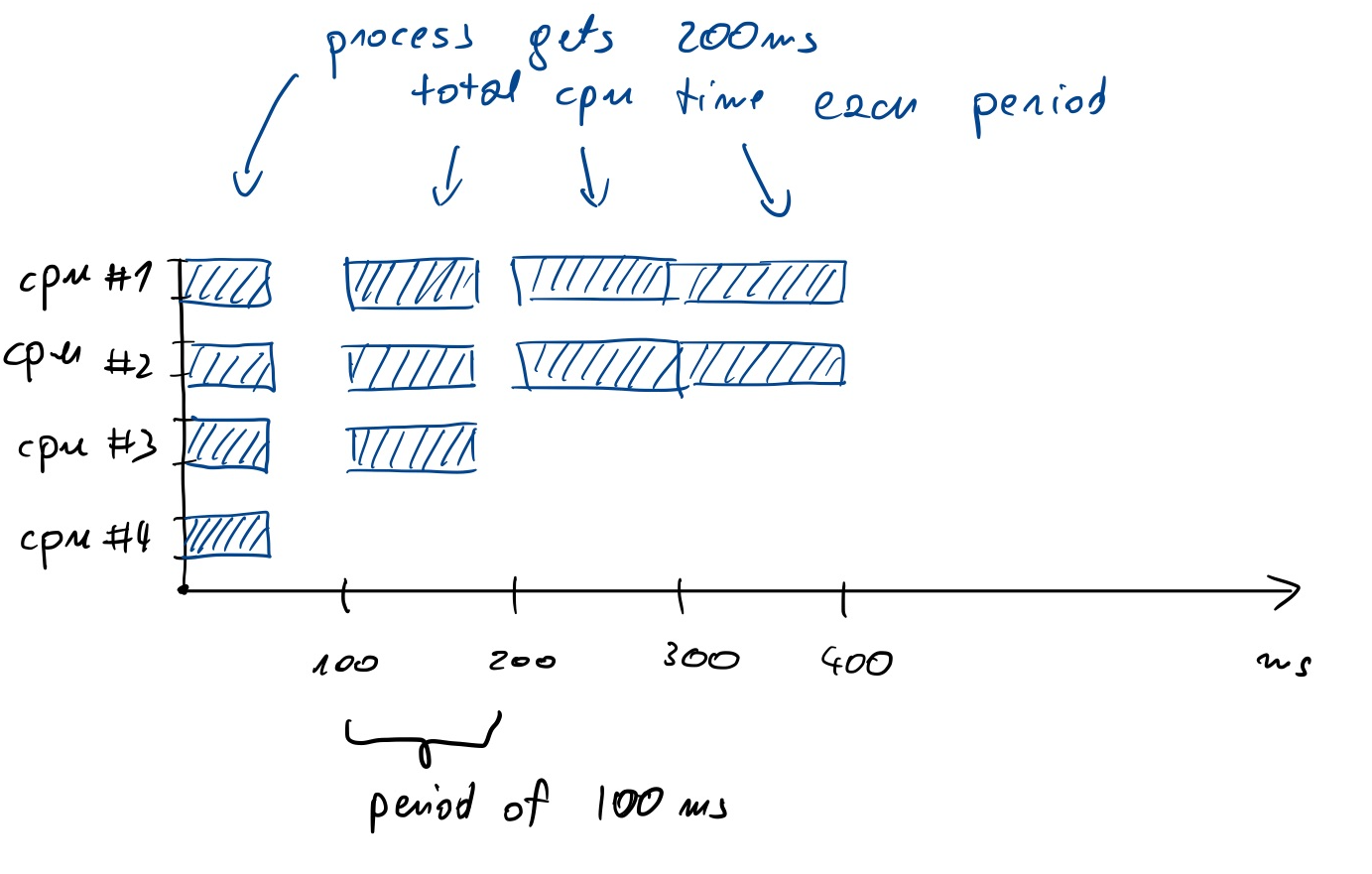
This situation is not a problem when we have a batch process or long running computation of some sort. This is problematic in the case of interactive applications, e.g. serving requests. Let’s say our service generates a reply in 10ms. If it happens to receive a request at 49ms into a period and uses all 4 cores, the response will be generated only in the next period. The reply for this request is generated in 60ms instead of 10ms; the tail latency increased.
We can prevent that by using GOMAXPROCS:
The
GOMAXPROCSvariable limits the number of operating system threads that can execute user-level Go code simultaneously.
I suggest to set it to no more than the quota.
Alternatively, use uber/automaxprocs:
Automatically set
GOMAXPROCSto match Linux container CPU quota. .. WhenGOMAXPROCSis increased above the CPU quota, we see P50 decrease slightly, but see significant increases to P99. We also see that the total RPS handled also decreases.
Note that selecting the value for GOMAXPROCS is a bit harder than for GOMEMLIMIT, because:
- Sometimes you are OK with the increased tail latency (e.g. in batch processing, or if each request already takes much longer to process than the CFS period).
- You may have your quota set quite high (or not set at all), but due to the system being under load, you are still throttled. In that case, you may want to set it to a lower value than the quota.
It’s best to test how setting the GOMAXPROCS affects the latency distribution for your service and load.
Summary
When deploying Go applications in containerized environments, it’s important to remember that the Go runtime is not aware of the CPU and memory constraints imposed by the container orchestrator. This can lead to suboptimal performance, including the risk of out-of-memory kills and increased tail latency.
Remember to configure GOMEMLIMIT and GOMAXPROCS. Or let heuristics from KimMachineGun/automemlimit and uber/automaxprocs configure it for you. You will avoid out-of-memory kills and improve tail latency.