AWS Lambda to invalidate CloudFront when S3 object changes
There are only two hard things in Computer Science: cache invalidation and naming things.
– Phil Karlton
In this post we will focus on cache invalidation.
Problem statement #
This blog is a static site hosted on S3 with CloudFront being used as a CDN / cache. Blog post about this setup.
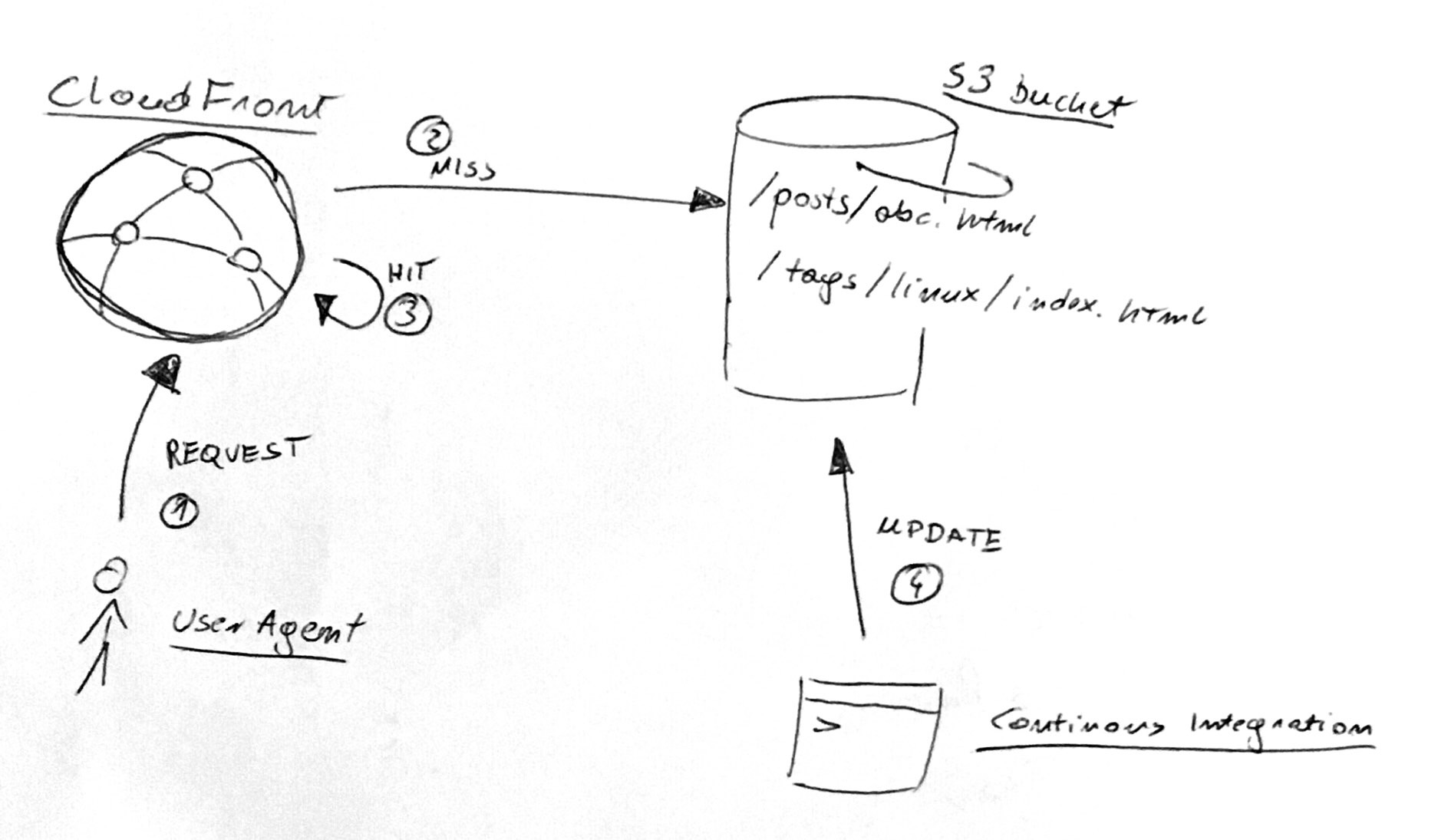
- UserAgent requests
kupczynski.info/posts/abc.htmlfrom CloudFront. - If this is not in the CloudFront cache, then we have a miss — CloudFront consults S3 bucket for an up-to-date version.
- On next requests to this resource it is in the CloudFront cache, so we have a hit. No need to consult S3 bucket.
- Occasionally, a post is updated by my Continuous Integration infrastructure.
The problem is how to serve an up-to-date version of a post. And make sure that we hit the cache most of the time.
Some more context:
- Posts are rarely added more than once a month.
- Adding a post changes 2–5 page (the post itself, main page, tag index pages, RSS).
- Posts are not edited often.
- A change in the layout may affect most, if not all of the pages; it is very rare.
<directory>/index.htmlis cached both under its path and under parent directory<directory>/
Solutions #
There are two broad categories of solutions here — (1) pull or (2) push.
Pull — CloudFront drives the cache invalidation. When it considers a resource to be stale, it asks S3 for its up-to-date version. When does it consider a resource to be stale? It assigned each resource a time to live (or TTL). TTL is controlled either via cache headers at source (S3 bucket) or, if not set, with cache defaults (CloudFront).
This is quite hard to get right in my use case. Posts change rarely, so they should be cached with a long TTL; on the other hand, if we edit a typo, etc. we want the change to be reflected as soon as possible. Index and tag pages have similar challenges — I want a new blog post to be shown there sooner rather than later. But then it sees no other updates for weeks.
Because of that, we’ll focus on the alternative.
Push #
In case of a push, some external system (ideally, the S3 itself) should notify the cache about an update to its storage and let the cache expire modified objects.
S3 doesn’t have such a feature, so let’s first take a quick look at the CI infrastructure. It updates S3 with the following command:
/usr/local/bin/aws s3 sync target s3://kupczynski.info --delete --size-only
This is how the output looks when we edit one of the posts:
## /usr/local/bin/aws s3 sync --dryrun target s3://kupczynski.info --delete --size-only
(dryrun) upload: target/2018/12/08/fire-and-motion.html to s3://kupczynski.info/2018/12/08/fire-and-motion.html
(dryrun) upload: target/rss.xml to s3://kupczynski.info/rss.xml
AWS CLI also supports JSON formatted output for more machine-friendly output
We can easily parse the output and write a script to issue the invalidations. We
could even add out custom logic of invalidating dir/ on a change to
dir/index.html. Or any other logic, like detecting that a change affects most
of the files and issue a wildcard invalidation instead.
However, I’ve looked for an excuse to play with AWS Lambda for quite some time, so let’s take a look at that.
AWS Lambda to the rescue #
You’ve probably heard the term serverless already. AWS Lambda allows you to define functions, and configure triggers for them to run. If you’re new to Lambda, the AWS product video [3 mins] embedded below does a good job explaining it.
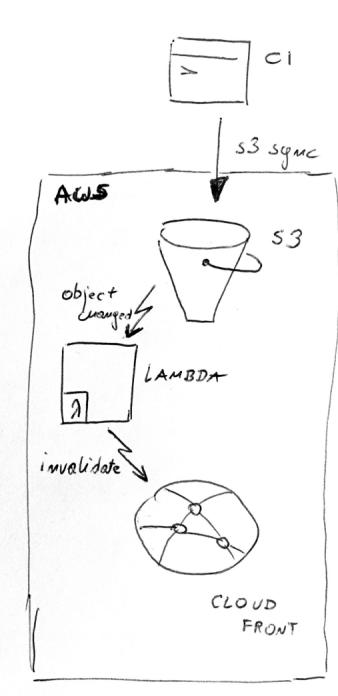
In our case, S3 can emit events when an object is modified or deleted. It emits an event per object. Out lambda will react to those events by issuing CloudFront invalidations. The flow is depicted below.
Code #
Here is our lambda:
import boto3 # (1)
import time
import os
def handle_s3_change(event, context): # (2)
paths = []
for items in event["Records"]:
key = items["s3"]["object"]["key"]
if key.endswith("index.html"):
paths.append("/" + key[:-10])
paths.append("/" + key)
print("Invalidating " + str(paths))
client = boto3.client('cloudfront')
batch = {
'Paths': {
'Quantity': len(paths),
'Items': paths
},
'CallerReference': str(time.time())
}
invalidation = client.create_invalidation( # (3)
DistributionId=os.environ['CLOUDFRONT_DISTRIBUTION_ID'], # (4)
InvalidationBatch=batch,
)
return batch
We can make a few interesting points here:
- We have access to the AWS SDKs, which makes it trivial to interact with
other services, like CloudFront. We see an example of this at
(3). - The function is an event handler, it takes the event as an argument. The AWS Lambda runtime takes care of calling it when an event arrives.
- Using the AWS SDK, we can easily interact with CloudFront.
- No need to hardcode the configuration, we can use environment variables. This function is generic and can be used without code change in your various environments.
The code itself is small and simple. No need to start a server or an event loop, no external dependencies. This is really nice.
Plumbing #
To make this lambda work, we need to configure some more AWS resources. If we use the Lambda IDE (built into AWS Management Console), then some of the configuration will be placed behind a wizard and visualized nicely. Which makes it quite easy and intuitive.
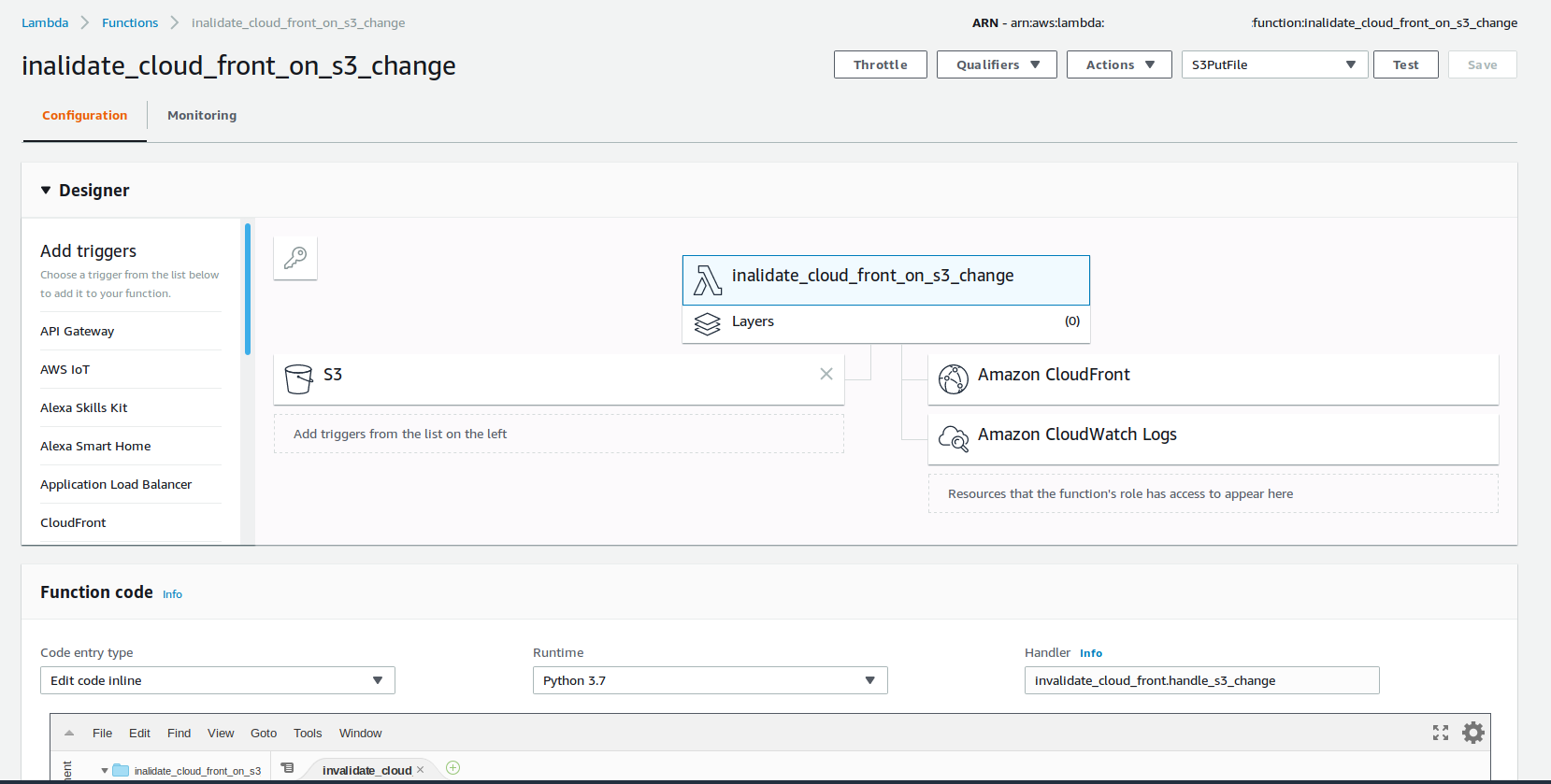
Past the experimentation phase, you most likely want to use some Infrastructure as Code (IaC) tool, like terraform. I plan to write another post on the anatomy of lambda, and what AWS resources are required, but if you are curious, then check my GitHub for a terraform spec of this function and all required resources.
Does it solve the problem? #
Yes, we can set the default TTL for a large value (e.g. 60 days), and in case of
any change to the site, we’ll invalidate CloudFront cache only for the changed
resource (and possibly it’s parent folder for index.html).
Cost #
I don’t have a lot of data yet, as I’ve set the lambda only a few days back; this is more of a guess-work at this point.
There are two things that cost us money here: Lambda invocations and CloudFront invalidations.
AWS charges for each invocation and for GB-seconds (RAM times number of seconds). The function is set to use the minimum 128MB of RAM and, according to data points I have so far, takes about 800ms to run. Let’s say we update 2000 objects monthly (it should be fewer). AWS has some free allowance, so this will cost me $0. I’m curious to validate it after a month.
CloudFront invalidation pricing is as follows:
No additional charge for the first 1,000 paths requested for invalidation each month. Thereafter, $0.005 per path requested for invalidation.
We pay $0 for up to 1000 paths (which is not the same as 1000 objects, as
index.html may result in two paths to invalidate) and $5 for 2000 paths. We
can see this is the faster-growing component of the two, however with my current
usage I expect it to be $0 most of the months.
Keep the cost low #
We do this exercise in the context of my personal blog. Latency is not critical and a cache miss is definitely acceptable. On the other hand, I want to keep the costs low. The most expensive thing with this solution is the monthly amount of paths to invalidate. We could reduce this number by aggregating them with a wildcard.
CloudFront allows you to put a trailing * at the end of the invalidation path.
E.g. /posts/2014/* will invalidate all of the posts written in 2014.
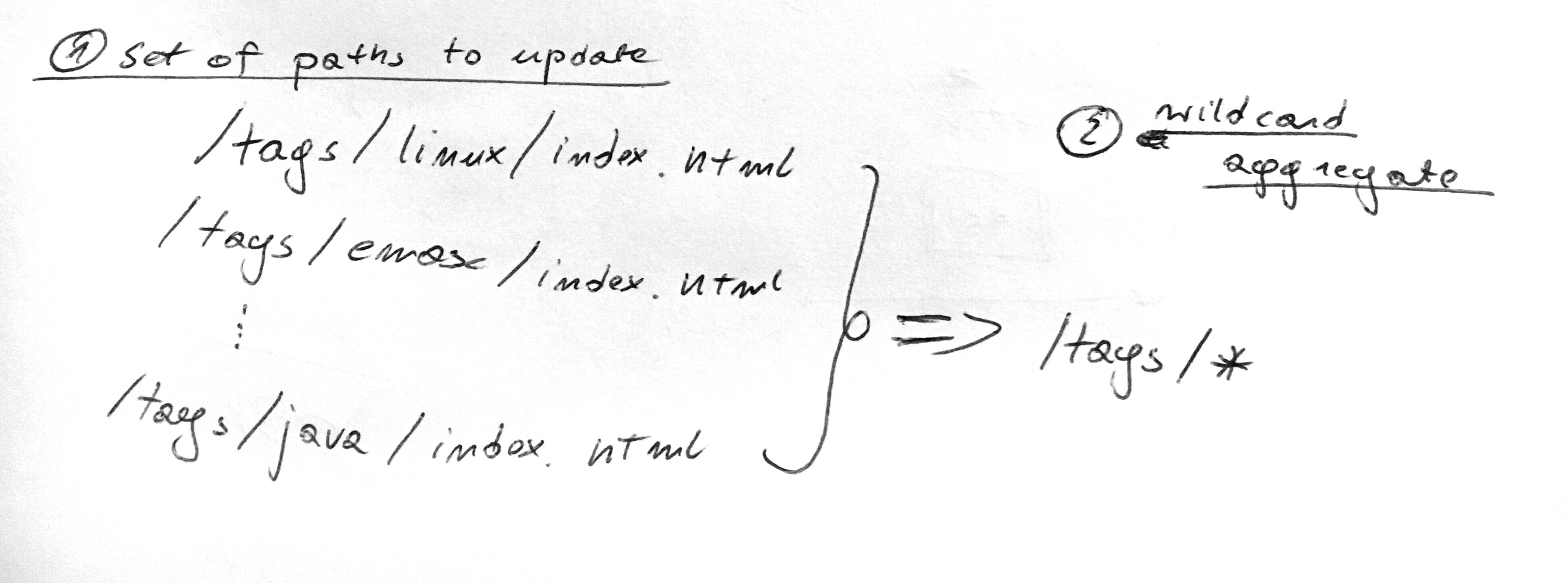
If we’ve parsed the output from our CI with a script, this script would operate on a set of all of the resources for the particular update. We could then use a heuristic, e.g. 5+ paths under a common prefix, to issue a wildcard invalidation instead. This would be useful in case of a page redesign, which can affect most of the pages in a single go.
Our lambda, however, operates in the context of a single object. Which means we can’t group or aggregate by a common prefix. I wonder if there’s an easy way to aggregate events, and operate only on aggregates.
Summary #
In the post we’ve specified a cache invalidation problem for an S3 hosted website cached behind CloudFront. We’ve shortly discussed pull vs push models. Finally, we presented a simple Lambda based solution and discussed its pricing implications. The solution offers some room for improvement, which we hope to explore in future posts.