JVM Class Data Sharing
This post describes how to enable Class Data Sharing (CDS) for a java app and what are the benefits of doing so.
I’ve recently seen a talk about CDS by Volker Simonis which was the inspiration to write this blogpost.
Table of Contents
What is Class Data Sharing? #
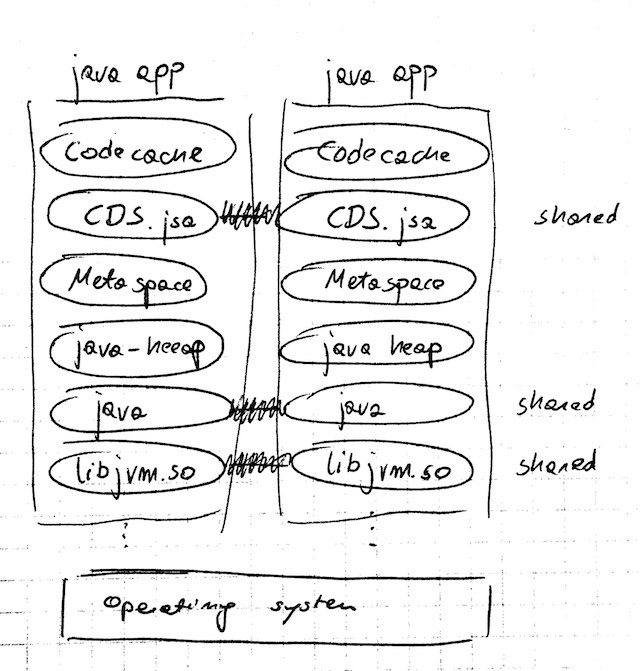
Class Data Sharing is a JVM feature, which allows multiple JVMs to share loaded classes (and some other things) via shared memory.
A basic CDS was available with Sun JVM since java 1.5. It was limited to system classes and serial GC only, so not widely applicable. In Oracle JDK 9 this finally became useful, with support of other GC algorithms and application classes. It was a commercial feature until JDK 10, where it became opensource.
CDS creates a memory mapped file, caching the internal representation of specified classes. This file (and its memory) can therefore be shared between JVMs, plus the loading of classes from the internal representation is faster than from a regular jar file.
It is worth noting that IBM Open J9 had a similar feature for a long time.
In this blog post we’ll investigate how to prepare such a CDS archive and look at potential benefits. We’ll use elasticsearch docker image to conduct the experiment.
Prepare CDS #
All of the code presented here is posted on github.
Intro — we need OpenJDK 10 #
Let’s use elasticsearch docker image to test the impact of class data sharing.
First, we need to repackage it with openjdk 10.
## Dockerfile-openjdk10
FROM docker.elastic.co/elasticsearch/elasticsearch-oss:6.2.4
COPY pkg/ /app/pkg
RUN cd /app/pkg && \
tar -zxf openjdk-10.0.1_linux-x64_bin.tar.gz && \
mkdir -p /opt/java && \
mv jdk-10.0.1 /opt/java
ENV JAVA_HOME /opt/java/jdk-10.0.1
Let’s create a Makefile, we’ll add more to it as we go:
## Makefile
.PHONY: help
help:
@ echo "# Elasticsearch and Class Data Sharing (CDS) experiment"
@ echo
@ echo "build-jdk10 - repackage elasticsearch-oss with openjdk10"
@ echo
@ echo "clean-cache - nuke the class list and cache"
@ echo "generate-class-list - list classes used by elasticsearch"
@ echo "dump-class-cache - dump the classes from the list to cache file"
@ echo "build-cds - repackge the class cache in the elasticsearch docker container"
@ echo
@ echo "run-{cds/nocds} - run elasticsearch with/without class data sharing"
@ echo
pkg/openjdk-10.0.1_linux-x64_bin.tar.gz:
@ wget -P pkg https://download.java.net/java/GA/jdk10/10.0.1/fb4372174a714e6b8c52526dc134031e/10/openjdk-10.0.1_linux-x64_bin.tar.gz
pkg: pkg/openjdk-10.0.1_linux-x64_bin.tar.gz
.PHONY: build-jdk10
build-jdk10: pkg
@ docker build -f Dockerfile-openjdk10 -t "ikupczynski/elasticsearch-oss:6.2.4-openjdk10" .
And now we can get our repackaged image:
make build-jdk10
Create a list of classes used by Elasticsearch #
We’re going to start elastics, make it respond to a simple request and
let it log all the classes it uses to a file
-XX:DumpLoadedClassList=/app/cache/elasticsearch_appcds. We need to
specifically enable the support for application classes with
-XX:+UseAppCDS, otherwise will limit ourselves to jdk classes only.
CWD := $(shell pwd)
.PHONY: clean-cache
clean-cache:
@ rm -rf cache/elasticsearch_appcds*
@ echo "Nuked cache"
cache/elasticsearch_appcds.cls:
@ touch cache/elasticsearch_appcds.cls
@ export ES_JAVA_OPTS="-XX:+UseAppCDS \
-XX:DumpLoadedClassList=/app/cache/elasticsearch_appcds.cls" && \
docker run \
-d --name generate-class-list \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-v $(CWD)/cache:/app/cache \
--env ES_JAVA_OPTS \
-it "ikupczynski/elasticsearch-oss:6.2.4-openjdk10"
@ echo "Waiting until elasticsearch starts"
@ bin/wait-on-elastic
@ docker rm -f generate-class-list
@ echo "Class list generated. Number of classes: "
@ wc -l cache/elasticsearch_appcds.cls
We start elasticsearch in the background (docker run -d) and wait
until it starts responding to requests with a following
script:
until $(curl --output /dev/null --silent --head --fail localhost:9200); do
printf '.'
sleep 1
done
If we run make cache/elasticsearch_appcds.cls we’ll get a list of
approximately 7k classes used by elasticsearch.
$ make cache/elasticsearch_appcds.cls
e2afbb966e1ad64d1296ada7c67a1038301834f8419aafa419ebbf74c7cd499b
Waiting until elasticsearch starts
...........generate-class-list
Class list generated. Number of classes:
7111 cache/elasticsearch_appcds.cls
$ head -n 5 cache/elasticsearch_appcds.cls
java/lang/Object
java/lang/String
java/io/Serializable
java/lang/Comparable
java/lang/CharSequence
$ tail -n 5 cache/elasticsearch_appcds.cls
org/elasticsearch/common/io/Streams$FlushOnCloseOutputStream
org/elasticsearch/Version$DeclaredVersionsHolder
com/fasterxml/jackson/core/io/JsonStringEncoder
com/fasterxml/jackson/core/util/ByteArrayBuilder
org/elasticsearch/common/bytes/PagedBytesReference$1
Note that the list is generate while your app is running, so if you load any classes manually later on, you should exercise this codepath. In our case we just wait until elasticsearch can respond to a simple rest request. This is not perfect, but good enough for our experiment.
JVM error #
Normally, the next step would be to take the elasticsearch_appcds
class list and use it to populate the cache file, however I’ve hit some
limit (either a JVM bug, or more likely, some memory limits or
docker-jvm interplay) and I needed to trim down the class list by 1/7 to
around 6k. See
error.org
for more details.
I leave the root cause investigation for some later time. Now, let’s just trim the class list.
## Workaround of the JVM error
cache/elasticsearch_appcds.cls-thin: cache/elasticsearch_appcds.cls
@ head -n 6218 cache/elasticsearch_appcds.cls > cache/elasticsearch_appcds.cls-thin
@ echo "Filtered the class list. Number of classes: "
@ wc -l cache/elasticsearch_appcds.cls-thin
generate-class-list: cache/elasticsearch_appcds.cls-thin
Prepopulate the class cache #
Now that we have the class list, let’s use it to pre-populate the class cache. Contrary to the previous step, here the jvm won’t run the app. It will start a process to go through the class list, load each of the classes and dump them to the cache file and stop the jvm.
cache/elasticsearch_appcds.jsa: generate-class-list
@ touch cache/elasticsearch_appcds.jsa
@ export ES_JAVA_OPTS="-Xshare:dump \
-XX:+UseAppCDS \
-XX:SharedClassListFile=/app/cache/elasticsearch_appcds.cls-thin \
-XX:+UnlockDiagnosticVMOptions \
-XX:SharedArchiveFile=/app/cache/elasticsearch_appcds.jsa" && \
docker run \
--rm --name dump-class-cache \
-e "discovery.type=single-node" \
-v $(CWD)/cache:/app/cache \
--env ES_JAVA_OPTS \
-it "ikupczynski/elasticsearch-oss:6.2.4-openjdk10"
dump-class-cache: generate-class-list cache/elasticsearch_appcds.jsa
Let’s try it out.
$ make dump-class-cache
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
narrow_klass_base = 0x0000000800000000, narrow_klass_shift = 3
Allocated temporary class space: 1073741824 bytes at 0x00000008c0000000
Allocated shared space: 3221225472 bytes at 0x0000000800000000
Loading classes to share ...
(...)
Loading classes to share: done.
Rewriting and linking classes ...
Preload Warning: Removed error class: org.apache.logging.log4j.core.async.AsyncLoggerContext
Rewriting and linking classes: done
Number of classes 7211
instance classes = 7087
obj array classes = 116
type array classes = 8
Updating ConstMethods ... done.
Removing unshareable information ... done.
Scanning all metaspace objects ...
Allocating RW objects ...
Allocating RO objects ...
Relocating embedded pointers ...
Relocating external roots ...
Dumping symbol table ...
Relocating SystemDictionary::_well_known_klasses[] ...
(...)
Removing java_mirror ... done.
mc space: 18184 [ 0.0% of total] out of 20480 bytes [ 88.8% used] at 0x0000000800000000
rw space: 18630320 [ 22.6% of total] out of 18632704 bytes [100.0% used] at 0x0000000800005000
ro space: 31856600 [ 38.6% of total] out of 31858688 bytes [100.0% used] at 0x00000008011ca000
md space: 6160 [ 0.0% of total] out of 8192 bytes [ 75.2% used] at 0x000000080302c000
od space: 31914104 [ 38.7% of total] out of 31916032 bytes [100.0% used] at 0x000000080302e000
total : 82425368 [100.0% of total] out of 82436096 bytes [100.0% used]
And the resulting file is 80Mb of pre-loaded classes:
$ ls -lah cache/elasticsearch_appcds.jsa
-r--r--r-- 1 igor staff 79M May 20 20:52 cache/elasticsearch_appcds.jsa
Package it with the container #
We have the class cache, now we can package it with the container.
Here is the dockerfile:
## Dockerfile-cds
FROM ikupczynski/elasticsearch-oss:6.2.4-openjdk10
COPY cache/ /app/cache
As you can see it is quite simple, it just copies the cache to the container.
And the complimentary Makefile addition:
CDS_IMAGE = ikupczynski/elasticsearch-oss:6.2.4-cds
.PHONY: build-cds
build-cds: dump-class-cache
@ docker build -f Dockerfile-cds -t $(CDS_IMAGE) .
I’ve build and pushed the image to dockerhub, so you can carry on from here with
docker pull ikupczynski/elasticsearch-oss:6.2.4-cds
Convenience targets to run elasticsearch #
Let’s define some make targets to let us run elasticsearch both with
and without CDS.
RUN_NO_CDS = export ES_JAVA_OPTS="-Xshare:off \
-Xlog:class+load:file=/app/logs/classload-nocds.log " && \
docker run \
-e "discovery.type=single-node" \
-v $(CWD)/cache:/app/cache \
-v $(CWD)/logs:/app/logs \
--env ES_JAVA_OPTS \
-it
.PHONY: clean-nocds-logs
clean-nocds-logs:
@ rm -f logs/classload-nocds.log*
.PHONY: run-nocds
run-nocds: clean-nocds-logs
@ $(RUN_NO_CDS) --rm $(CDS_IMAGE)
## `time-nocds` given mostly for illustration, it is not acurate
.PHONY: time-nocds
time-nocds:
@ $(RUN_NO_CDS) -p 9200:9200 --name run-no-cds -d $(CDS_IMAGE)
@ echo "Timing the wait on elastic"
@ time bin/wait-on-elastic
@ docker rm -f run-no-cds
RUN_CDS = export ES_JAVA_OPTS="-Xshare:on \
-Xlog:class+load:file=/app/logs/classload-cds.log \
-XX:+UseAppCDS \
-XX:SharedClassListFile=/app/cache/elasticsearch_appcds.cls-thin \
-XX:+UnlockDiagnosticVMOptions \
-XX:SharedArchiveFile=/app/cache/elasticsearch_appcds.jsa" && \
docker run \
-e "discovery.type=single-node" \
-v $(CWD)/cache:/app/cache \
-v $(CWD)/logs:/app/logs \
--env ES_JAVA_OPTS \
-it
.PHONY: clean-cds-logs
clean-cds-logs:
@ rm -f logs/classload-cds.log*
.PHONY: run-cds
run-cds:
@ $(RUN_CDS) --rm $(CDS_IMAGE)
## `time-cds` given mostly for illustration, it is not acurate
.PHONY: time-cds
time-cds:
@ $(RUN_CDS) -p 9200:9200 --name run-cds -d $(CDS_IMAGE)
@ echo "Timing the wait on elastic"
@ time bin/wait-on-elastic
@ docker rm -f run-cds
Now we can run elasticsearch with or without CDS:
make run-cds
make run-nocds
Experiment #
Let’s see how the classes are loaded #
We can run both versions in the terminal, and then inspect logs:
$ make time-nocds
## ...
$ make time-cds
## ...
$ grep 'org.elasticsearch.bootstrap.Bootstrap ' logs/*
logs/classload-cds.log:[1.370s][info][class,load] org.elasticsearch.bootstrap.Bootstrap source: shared objects file
logs/classload-nocds.log:[2.696s][info][class,load] org.elasticsearch.bootstrap.Bootstrap source: file:/usr/share/elasticsearch/lib/elasticsearch-6.2.4.jar
As we can see, with the class data sharing, we’ve loaded the main class
from shared objects file, which means the class cache we’ve created.
In case of nocds the file is loaded from the jar. All as expected.
We also see that the cds version loaded the main class over a second
faster, and this number was fairly consistent across various runs I did
to write this post. I wouldn’t trust it, as it wasn’t a rigorous
benchmark — I run on a dev laptop with many variables to account for. If
you are in a business of (re-)starting java apps often, generate a class
cache and try to compare startup times for you use case / app.
Let’s also see how many classes where actually loaded from cache.
$ grep -c 'shared objects file' logs/classload-cds.log
2028
Memory usage #
Let’s start with no class data sharing:
$ make run-nocds # 4 times, different terminals
## (...)
$ docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
371268a8263b vigilant_neumann 0.91% 1.168GiB / 7.787GiB 15.00% 858B / 0B 0B / 254kB 28
5137554b5e86 pensive_kepler 0.16% 1.164GiB / 7.787GiB 14.95% 858B / 0B 0B / 254kB 28
9fd0a493d7a2 vibrant_albattani 0.18% 1.174GiB / 7.787GiB 15.08% 858B / 0B 0B / 254kB 28
5cfb3f1d7a8e vibrant_shtern 0.20% 1.17GiB / 7.787GiB 15.03% 1.04kB / 0B 8.19kB / 254kB 28
Reported mem usage: 1.164, 1.168, 1.170, 1.174 [GiB]
And with class data sharing
$ make run-cds # 4 times
## (...)
$ docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
4e29db4f3dca inspiring_volhard 0.97% 1.154GiB / 7.787GiB 14.82% 718B / 0B 8.19kB / 254kB 28
2841355336be awesome_shockley 0.31% 1.153GiB / 7.787GiB 14.81% 788B / 0B 0B / 254kB 28
1fe95a004665 naughty_goldberg 0.39% 1.171GiB / 7.787GiB 15.04% 788B / 0B 0B / 254kB 28
513955f2d550 compassionate_montalcini 0.27% 1.152GiB / 7.787GiB 14.80% 968B / 0B 0B / 254kB 28
Reported mem usage: 1.152, 1.153, 1.154, 1.171 [GiB]
Again, not really a benchmark, but we can see a 5--20 MiB improvement.
Recap #
To create a class data archive, we need to:
Run the application, while dumping the class list
-XX:+UseAppCDS -XX:DumpLoadedClassList=/class-list.clsGenerate the archive file from this list
-Xshare:dump \ -XX:+UseAppCDS \ -XX:SharedClassListFile=/class-list.cls \ -XX:+UnlockDiagnosticVMOptions \ -XX:SharedArchiveFile=/archive.jsaRun the app with the archive
-Xshare:on \ -XX:+UseAppCDS \ -XX:SharedClassListFile=/class-list.cls \ -XX:+UnlockDiagnosticVMOptions \ -XX:SharedArchiveFile=/archive.jsa
The internal representation may be architecture dependent, so should be generated on an env close to the target.
As a result of that, few dozen megabytes worth of java classes can be shared across JVMs; plus we’ll shave a few seconds from the startup time. In case of elasticsearch, these are not huge savings. On the other hand, if you run multiple copies of your app, or this is a script, where lower startup time improves the UX greatly, you should consider using Class Data Sharing. Coincidentally, if you run a serverless platform, both of these conditions apply.
Conclusions #
Class data sharing allows for shorter startup times and lower memory usage (if running multiple instances). Volker Simonis reports 30% statup time improvement for JRuby. If you need to start your app often (e.g. scripts) or run multiple copies of it (orchestration, serverless), and you are OpenJDK 10 compatible (for application class sharing) give it a try.
Ideas for future posts #
- Why does JVM complain about full 7k list of classes for elasticsearch?
- What are the gains with scala, which is known to generate a lot of classes.